基于大同地区SCADA系统的海迅实时数据库存储原理
摘要:山西省电力公司大同供电分公司的数据采集与监视控制系统(SCADA)以江苏瑞中股份有限公司海迅
(Highsoon)实时数据库为基础。本文介绍了海迅实时数据库的结构设计,通过分布式体系架构、混合压
缩磁盘缓存、并发处理机制以及多连接多线程方式完成了海量数据存储,满足了数据采集与监视控制系统
关键词:数据采集与监视控制系统(SCADA)、海迅(Highsoon)实时数据库、分布式、混合压缩磁盘缓存、并发处理机制、多线程
1. 前言
考虑大同供电分公司调度自动化系统现在和以后要处理的遥测遥信量的数量,要形成海量的信息。海量信息的需求包括两个方面:1、采集的遥测遥信规非常模大,随着不断快速扩大的电网规模和不断增强的电网互联,SCADA系统面对的采集点越来越多,目前大同地区调度自动化的采集量可以达到上百个站点,而大同地区未来可能面临50-100万的数据采集规模。2、采集频率高,传统的分钟级周期采集无法反映电网的真实运行轨迹,而变化采样需要秒级的采集精度。以上两个需求都对数据库系统软件的实时性提出更为苛刻的要求[1] [2] 。
2. 大同供电分公司海迅(Highsoon)数据库的设计方案
1)海迅(highsoon)实时数据库设计目标
海迅实时数据库在总结国内外同类产品的基础上按照电力系统的特点采用分布式体系架构,可运行于不同的操作系统平台,实现海量实时数据的自动采集、历史数据的压缩存储、高效的查询检索和统计分析,能够在线存储数十万甚至上百万采集点的数年历史数据,采集分辨率可达微秒,提供一系列的套件应用工具和完整的二次开发环境,大同供电公司可构建自己的实时应用环境,也可方便地实现无缝的嵌入式应用。
2)海迅(highsoon)实时数据库体系架构
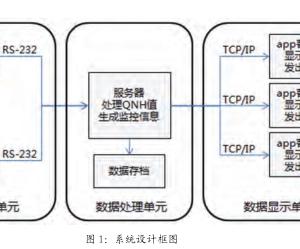
海迅实时数据库在物理上分散于计算机网络的各个节点,但在逻辑上却属于一个整体的数据库管理系统。海迅数据库系统分为两大部分,第一部分由数据处理服务、命名服务、二次开发接口组成数据库核心,其中,数据处理服务器是海迅实时数据库的核心,完成海量数据的压缩存储和查询功能;命名服务器则主要完成服务名转换和数据库授权控制功能;第二部分为数据库应用套件,主要包括客户端、图形组态、趋势分析、报表、计算、WEB发布等。
海迅实时数据库的体系架构可以用下图来示意表示:
图1 海迅实时数据库体系架构
如上图所示,海迅实时数据库数据处理服务器在系统启动时,向命名服务器注册其服务名称和服务地址(包括服务IP和端口号);客户端在访问数据处理服务器之前,先与命名服务器建立连接,查询取得需要访问的数据处理服务器的服务地址,然后建立其与数据处理服务器之间的服务连接,然后就可以进行数据存储和访问工作了。由于数据访问客户端只需要具有数据处理服务器的逻辑服务名信息就可以访问,当数据处理服务器的服务地址发生变化时,数据访问客户端不受影响,从而达到数据的物理位置无关性的目标[3]。
在海迅实时数据库中,一个数据处理服务可以同时向最多两个命名服务注册,以实现命名服务的冗余备份,提高命名服务的可靠性;同时,一个命名服务可以同时管理多个数据处理服务,从而保证整个系统的性能和容量可以平滑升级。
3)海迅(highsoon)实时数据库数据处理
海迅实时数据库采用2种标识符(内部序号和名称)来标识所存储的数据,内部序号为整型数,用于数据库内部标示,用户不可更改,名称标识符由用户指定最多可以由31个ASCII字符组成,在同一个数据处理服务上,名称标识符必须具有唯一性,在不同的数据处理服务器上,数据点名称标识符可以复用。
海迅实时数据库将存储的历史数据定义为事件(Event),事件是实时数据库数据处理的最小单元。事件包括两种类型:数值型和字符型。
数值型事件由三部分组成,包括:时标(Timestamp)、值(Value)和质量标志(Status)。其中,时标由两个4字节整数(hours和usecs)表示,其中hours表示的是当前时刻到公元元年的小时数,usecs则表示当前时刻到上一个整点时刻的微秒数,时标的表示精度为1微秒,可以表达的时间范围则是从公元元年到公元后490,000年;数据值由单精度浮点数(4字节)或双精度浮点数(8字节)表示;质量标志由一个4字节整数表示。因此,一个完整的数值型事件占用的原始空间为16字节或者20字节。
HS存储的单精度浮点数数值型事件可以用下图表示:
图2 单精度浮点数数值型事件
字符型事件与数值型类似,只是数据值部分由64个ASCII字符组成表示,一个完整的字符型事件占用的原始空间为76字节。
对于数值型数据点,海迅实时数据库将其分为2种类型:离散数据点和连续数据点。离散数据点对应工业自动化系统中的变化不连续的量测量,例如电力系统的遥信量、设备运行状态等;连续数据点对应连续变化的量测量,如电力系统的电压、电流、有功、相角等物理上连续变化的数据。对于离散数据点,海迅实时数据库对其历史数据序列只进行无损压缩处理,在查询时也只返回所存储的原始值,不进行插值处理;对于连续数据点,海迅实时数据库根据用户所设置的有损压缩允许误差,对其历史数据序列进行线性带宽压缩或者直线压缩,有损压缩处理后的结果再经过无损压缩处理后存储在磁盘上。对于字符型数据,海迅实时数据库只使用无损压缩方法对其进行压缩;与数值型数据类似,用户也可以设定其历史数据保留时间,如果其实际历史数据保留时间超过了设定值,系统将自动删除最早的历史数据,使历史数据的保留时间用户设定的要求。在存储压缩数据之前,系统首先检查相应数据点历史数据的实际保留时间是否超过了用户的设定值,如果超过了设定值,数据处理服务器首先删除该数据点最早的历史数据,然后再将压缩数据存储到磁盘文件中,这样就可以达到存储空间循环利用的目的。
海迅实时数据库的数据处理流程可以用下图来表示:
图3 海迅实时数据库数据处理流程
针对需要处理的数值型事件的特点,海迅实时数据库采用改良的哈弗曼压缩算法对需要存储的时序数据进行无损压缩处理,改良的内容包括:将浮点数按照IEEE-754的表示方法分解为符号位(1位)、指数位(7位)和小数位(23位),对于小数位则进一步按照压缩存储精度要求将其截断,最后将这三部分分别进行压缩;求取相邻事件点时标的差值,存储起始时标值,并对时标差值序列进行压缩处理;对质量位直接进行压缩处理
通过以上所述的处理措施,在不降低压缩速度的情况下,数据压缩率平均可以提高1~2倍。在常规情况下,海迅实时数据库的无损压缩率可以达到10倍以上。
对于连续变化的数据点,海迅实时数据库采用特殊设计的线性带宽压缩算法对其历史序列进行压缩处理,通过设置合理的有损压缩精度,在满足应用精度要求的情况下,有损压缩的压缩率一般可以达到5倍以上。海迅实时数据库的压缩率为有损压缩、无损压缩的综合乘积,在常规情况下数据综合压缩率可以达到50倍以上。
现代计算机系统一般都支持多线程并发处理,在硬件上一般都具有2个或2个以上的CPU(处理器核心)。海迅实时数据库的数据处理服务器采用线程池结构,对用户所提交的数据存储和查询请求并行处理,包括并行压缩、并行存储、并行搜索、并行读取,消除了软件结构对系统吞吐量的限制,大大提高了系统整体性能。目前,在普通的双核PC机上处理性能可以达到每秒千万事件以上,在同等软硬件环境下其性能是其他同类产品性能的10倍以上。
除了对历史数据序列进行压缩处理之外,海迅实时数据库同时还对历史数据进行了实时的最大、最小值统计,统计结果与压缩处理后的结果一起存储,这样做的好处是当上层应用需要对大范围时间跨度的数据进行最大、最小值统计分析时,系统可以利用已经预先处理好的统计结果快速给出结果,从而大大加快统计分析的处理速度。
4)海迅(highsoon)实时数据库实时高速吞吐
海迅实时数据库系统将实时数据库、历史数据库以及数据缓存管理的有机结合,在程序设计上充分挖掘了现代处理器多核多CPU技术、操作系统技术、存储器技术和网络通讯技术的潜力。
海迅实时数据库高效运行的关键是如何处理客户端请求并与磁盘文件交互,因此充分发挥现代计算机系统的潜力是实时数据库能否取得成功的一个关键因素。
常规情况下,客户端通过网络链接向分布式实时数据库系统提交数据,服务端的处理线程与之对应,这种处理模式实际上很难实现高效运行。现代计算机系统中多路多核CPU技术已非常普遍,计算机的处理能力今非昔比,网络速度也实现了由百兆向千兆的转变,而物理磁盘读写速度依然是整个系统的处理瓶颈,实时数据库的高速处理能力与磁盘读写的矛盾非常突出。因此在这种情况下数据处理环节需要充分考虑如何在较慢的磁盘I/O与高速数据吞吐间的平衡,同时需要将多核、多CPU的能力充分进行应用,将现代计算机的处理能力充分发挥出来。
为了达到高速处理的要求,海迅实时数据库采用线程池技术实现并行处理数据写入请求。充分协调网络通讯和报文处理,使得多个CPU(多核)可以并行处理来自一个TCP链接上的多个请求报文,也就是将一个TCP连接上的报文处理任务并行化,从而达到高效处理的目标。并行化处理技术在写入数据时将有效地提升服务端数据处理的速度,经过实际测试使用单个客户端(单线程)向服务端提交数据,数据处理的速度可以达到千万事件每秒。
图5 高效的数据处理过程
对于数据读取而言同样可以采用线程池技术并行处理不同客户端的数据请求。系统设置高速缓存区,采用类似关系型数据库的LRU(Least Recently Used)策略,将最常用的数据保持在高速缓存中,在并发查询中实现数据共享,从而达到并发高效访问的目标。并行化处理技术在读取数据时有效地提升了服务端的响应速度。
图6 高效的查询速度过程
3. 结束语
海迅实时数据库系统的内部设计是根据电力生产过程中现场数据(遥测、遥信)的特点设计专门的压缩算法,根据数据的特性分为离散和连续型,并分别采用不同的压缩方式,并根据用户的需求,根据要求的精度,得到不同的压缩率。发挥多核的优势,将报文任务并行化,利用高速缓存使较慢的磁盘I/O与高速数据吞吐之间达到平衡。
参考文献
[1]叶 彤,吴钦章,蒋 平.实时数据库的应用研究[J].光电工程,2004,31(6):70-72
[2]刘吉臻,房方,牛玉广.电力企业中的实时数据库技术[J].中国电力,2004,37(2):73-78