基于反馈调度的 MapReduce 负载均衡分区算法研究
摘要:MapReduce 是一种处理大规模数据的并行计算模型,针对传统模型中 reduce 阶段各结点负载不均衡的问题,提出reduce 阶段负载均衡分区算法。算法将 map 阶段产生的中间数据划分为更多的分区,减少了每个分区的工作量,引入了反馈机制来进一步提高调度策略的性能,每次给 reducetask 分配都是基于反馈信息选择最优的分区,reducetask 完成工作之后会继续获得新的分区,直到所有的分区都被分配完毕,实现了动态调节各 reducetask 的负载。通过重写 Hadoop平台内核实现了算法并进行了实验分析,结果表明,该算法在不影响 MapReduce 模型的情况下显著地缩短了任务的处理时间。
关键词:MapReduce 分区算法;负载均衡;反馈机制;Hadoop;中图分类号:F724.6 文献标识码:A 文章编号:1673-1131(2015)10-0041-02.
0 引言
随着云计算的发展,软件即服务、平台即服务技术的推广,涉及海量数据处理的应用如雨后春笋般。Google 在 2004 年提出了用于海量数据的并行处理模型——MapReduce。虽然MapReduce 模作为并行数据处理工具取得了巨大的成功,但是在需要进行如连接、聚集等复杂计算的场景中,MapReduce的性能并不尽如人意。数据倾斜是严重影响 MapReduce 性能的因素之一。MapReduce 模型所提供的用于解决掉队者的备份任务的方法,然而 MapReduce 模型的备份任务并不能有效地解决数据倾斜带来集群效率下降的问题。针对以上的问题,本文做了如下的工作:本文在 RBPA 算法的基础上通过采样的方法获得节点处理速度的反馈信息,用于预估任务的期望时间,优化调度算法,选择最适合的分区放入处理中队列。以提高在异构环境下调度策略的精确度。
1 MapReduce 模型及相关研究
1.1 MapReduce
是 Google 提出用来简化分布式系统的编程模型。应用程序开发人员只需将精力放在应用程序本身上,而对于集群的处理问题,包括可靠性、可扩展性、可用性等,则交由平台来处理。MapReduce 通过“Map(映射)”和“Reduce(规约)”两个简单的概念来构成运算基本单元。用户只需提供 Map 函数和 Reduce 函数即可并行处理海量数据,极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。
1.2 相关研究
周家帅 [4] 等对当前的 MapReduce 框架进行拓展,根据对Map 端中间结果的采样来动态确定 Reduce 任务数目以及划分函数,保证 Reduce 任务的负载均衡;陶永才、石磊[5]提出在异构环境下,较之现有 Hadoop、Cloud-MR 减少了节点间数据传输和备份任务运行,缩短了作业完成时间。傅杰[6]等人提出了一种周期性 MapReduce 作业的负载均衡策略,根据采样的方式获取整体近似分布情况,并结合历史数据计算数据权重信息的方法进行分区,避免了 reduce 阶段的数据倾斜。
2 reduce 阶段基于反馈的动态分配分区算法
2.1 RBPA
RBPA 算法将 map 阶段产生的中间数据划分为更多的分区,减少了每个分区的工作量,每次给 reducetask 分配一个分 区,reducetask完成一个分区的工作之后会继续获得新的分区,直到所有的分区都被分配完毕,实现了动态调节reducetask的负载。
2.2 基于反馈的动态分区算法
本节针对上述的问题,在以上算法的基础上,给出一个相对通用的分区数量,和基于反馈策略的负载调度算法。
首先,在不考虑节点频繁地调度数据产生的时间消耗的情况下,分区的数量不应该超过 reducer 节点的 5 倍,以经验而言取 3 倍为最好。有关分区数量 x 的取值验证和对分区算法的影响在实验阶段进行详细的讨论。
2.3 算法描述
算法步骤:
(1)使用 partition 函数将集合划分为 x*n 个子集,每个子集代表一个分区,其中 n 代表 reducetask 的数量,系数 x 代表了子集划分的程度,x 越大子集就越多;
(2)每一个 Maptask 在 map 结束后将 n 到 x *n 的分区的编号和数据量发送给 Jobtracker;
(3)jobtracker 将得到的分区号码放入未分配分区队列;(4)如果所有 maptask 都已经完成则 reducetask 拉取从 0到 n-1 的分区数据,否则回到步骤 3;
(5)开始对输入的数据进行监测,统计一段时间内输入数据的消耗量,得出各个 reducer 的输入数据消耗速度和期望执行时间,则计算得出每个 reducer 在期望时间内处理数据的期望值;
(6)完成任务的reducetask向Jobtracker请求更多的工作;(7)jobtracker 从分区中选择选取的分区为最接近该 reducer 处理数据的期望值,并在列表中删除该分区的编号 m。
reducetask 拉取 m 的数据,进行处理。
3 实验结果与分析
实验的环境选用异构环境,选取 Hadoop[3]作为实验平台,由 8 台物理机组成的集群。实验所采用的测试方法为利用Hadoop 平台,本文提出改进 RBPA 算法分别与标准Hadoop性能和 RBPA 算法进行对比。为使实验结果具有可比性,以标准Hadoop 的运行时间为标准,对实验结果进行了标准化处理。
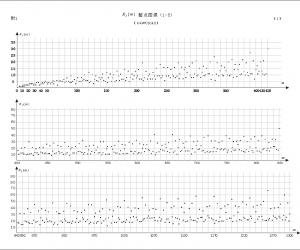
引入反馈机制后的算法执行时间如图 1 所示。从实验结果可以的看出 RBAP 算法相对于标准 Hadoop 有较好的执行效率,稳定性也有所提高。调度算法引入了反馈机制的改进RBPA 算法,相对于 RBAP 算法在性能有显著的提升。 4 结语本文提出了改进 RBPA 算法该算法可以动态地给各个 reducetask分配待处理的数据,基于反馈机制来智能地对每个分区进行调度,从而消除瓶颈,减少任务运行的时间。通过实验分析,证明了本文提出的算法能够很好地在 reduce 阶段负载均衡,其整体的稳定性也是得到提升。 参考文献:
[1] Dean J, Ghemawat S. Mapreduce: simplified data processing on large clusters. Communications of the ACM, 2008, 51(1):107-113
[2] 万聪,王翠荣,王聪,贾朔. MapReduce 模型中 reduce 阶段负载均衡分区算法研究[J]. 小型微型计算机系统.2015(2)2:240-243
[3] 刘刚,候宾,翟周伟.Hadoop——开源云计算平台[M].北京:北京邮电大学出版社,2011:95-101
[4] 周家帅,王琦,高军. 一种基于动态划分的 MapReduce 负载均衡方法[J]. 计算机研究与发展.2013(50):369-377
[5] 陶永才,石磊.异构资源环境下的MapReduce 性能优化[J].小型微型计算机系统.2013(2):287-29
[6] 傅杰,都志辉.一种周期性 MapReduce 作业的负载均衡策略[J].计算机科学.2013,40(3):38-40
作者简介:韩宏莹(1990-),男,硕士,研究方向为数据挖掘;刘寒梅(1972-),女,硕士,副教授,研究方向为数据挖掘。