基于Hadoop平台的电力行业大数据分析技术应用研究
摘要:本文通过对基于Hadoop平台的电力行业大数据分析技术研究,构建了结构化和非结构化数据抽取模型,及基于map/reduce的数据分析模型。实现发电、输电、变电、配电、用电等各环节数据的共享融合,在数据挖掘分析上由原来的点状分析,过渡到跨专业的网状数据分析,进一步提高了分析精度和分析效率。
关键字:Hadoop、电力行业、大数据分析
一、引言:
随着互联网+时代的到来,各行业数据的共享与融合越来越迫切。电力生产关系民生和经济发展,随着电力信息化的发展,涉及发电、输电、变电、配电、用电等各个环节的数据呈爆发性增长,PB数量级的数据,已无法通过传统的数据管理、抽取、分析技术挖掘数据间的多重关联关系,从而更有效的实现电力风险预警,提高生产效率和智能调度功能。
二、hadoop平台介绍
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台。以Hadoop分布式文件系统和MapReduce为核心的Hadoop为用户提供了系统底层细节透明的分布式基础架构。HDFS的高容错性、高伸缩性等优点允许用户将Hadoop部署在低廉的硬件上,形成分布式系统,MapReduce分布式编程模型允许用户在不了解分布式系统底层细节的情况下开发并行应用程序。所以用户可以利用Hadoop轻松地组织计算机资源,从而搭建自己的分布式计算平台,并且可以充分利用集群的计算和存储能力,完成海量数据的处理。
Avro是doug cutting主持的RPC项目,有点类似Google的protobuf和Facebook的thrift。是用于数据序列化的系统。提供了丰富的数据结构类型、快速可压缩的二进制数据格式、存储持久性数据的文件集、远程PRC调用以及简单的动态语言集成功能。
实现了MapReduce编程框架,用于大规模数据集的并行运算。能够使编程人员在不理解分布式并行编程概念的情况下也能方便将自己的程序运行在分布式系统上。
HDFS分布式文件系统,其设计目标包括:检测和快速恢复硬件故障;数据流的访问;简化一致性模型等。
Zookeeper是Google的Chubby一个开源的实现。它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
Pig是SQL-like语言,是在MapReduce上构建的一种高级查询语言,把一些运算编译进MapReduce模型的Map和Reduce中,并且用户可以定义自己的功能。Yahoo网格运算部门开发的又一个克隆Google的项目Sawzall。
Chukwa是基于Hadoop的大集群监控系统,是开源的数据搜集系统。通过HDFS来存储数据,并依赖MapReduce 来处理数据。
三、数据抽取分析模型
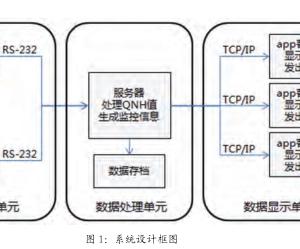
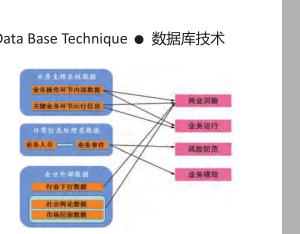
目前电力行业数据包含结构化数据如常规oracle,MySQL等数据库类型,同时也存在大量log日志文件,e文件等非结构化数据,为能全面有效的实现多业务,多数据综合建模分析,设计如图2所示,数据处理模型。主要由数据抽取、格式清洗和DFS分布式文件系统构成,同时为下一步大数据建模分析打好基础。
数据抽取模块主要负责从原业务系统获得结构化和非结构化业务数据。通过在数据抽取工具中配置前端机器名称、端口号、加密用户名密码、数据表等信息,实现结构化数据的抽取工作。对于日志类文件由于在原服务运行期间日志文件是持续写入状态,因此必须在原系统设置,系统日志按时间节点分割,一般可按具体业务运行情况和日志产生量和产生大小进行设定,避免因日志文件过大或网络繁忙,在抽取时对业务造成影响。
格式清洗模块主要是对原始数据中多种不同配置格式进行统一,特别是对非结构化数据,需定义每个字段的含义和位置以及统一分隔符,同时还会去掉一些记录不完整的坏数据,保证数据的格式统一,信息完成。最后导入HDFS文件系统进行存储。
数据分析通过Map/Reduce操作实现,通过设计业务分析模型,定位此项数据分析所需输入数据,并将数据数据分割成若干独立的块,并根据Inputformat把资料读入成一组(key,value)对,然后通过mapper count分给不同的mapper进行处理。再设计模型中,通过设置满足要求的map任务值,并引入哈希算法,将mapper对应初始的(initialkey,initialvalue)生成中间数据集(interkey,intervalue)划分为多个任务,将模值相等的任务丢到统一节点上计算,以实现比较平衡的分类效果。
Reducer对mapper产生的(interkey,intervalue)中间数据集,进行驱虫、过滤等后期处理后,得到结果。为实现输出文件格式支持通过key来高效的自由访问,并得到有序的数据输出,在reducer中加入排序环节,将所有的中间数据集根据key来排序的。这样每个小块都很容易生成一个序列化的输出文件。
通过展示系统,实现各业务模型数据分析结果图形化的展示在监控大屏上,同时桌面用户还可通过浏览器或客户端在终端上查询分析结果。
四、总结
通过hadoop平台构建电力行业大数据分析模型,可按照业务需要进行灵活进行组合,提高各专业间的数据共享融合,实现由点状业务分析模式,到贯穿“三集五大”各专业的网状业务分析模式,可进一步提高电网的健壮性、互动性和智能化,为社会经济稳定发展提供保障。