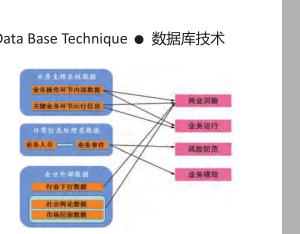
基于质量安全信息的舆情监测系统研究
摘要:近年来我国产品质量安全问题频繁发生,不仅引起了社会恐慌而且造成了国家巨大的经济损失,甚至在一定程度上会影响我国在国际贸易中的信誉。产品质量危机是公共危机的一种形式,但是其安全问题是涉及范围最广、影响公众生命健康最直接的一种公共危机。由于网上的信息量十分巨大,仅依靠人工的方法难以应对网上海量信息的收集和处理,需要加强相关信息技术的研究,形成一套自动化的网络舆情监控系统,及时应对网络舆情,由被动防堵,化为主动梳理、引导。
关键词:舆情、风险监测、质量安全
1、引言
近年来,随着新媒体的迅猛发展, 我国网络舆情的影响日益巨大。自2008年以来, “三聚氰胺”, “一滴香”、“瘦肉精”事件以及近期出现的“摇摇车”、“电梯事故”等一系列质量安全问题的出现,都在社会中产生了巨大的负面影响,产品质量安全的网络舆情的数量和影响持续上升,对政府舆论应对能力提出新的挑战,加强产品质量安全网络舆情监控管理研究的现实需求十分迫切。
当前国内在国内质检数据较为封闭的环境下,与互联网的联动和应用也预示着质检行业在大数据时代中的一种尝试。
2、舆情检索技术
网络舆情监测系统是一项复杂而庞大工程,它涵盖了几乎所有的互联网领域的基本技术,但从系统的功能实现上看,舆情监测系统的关键技术是由数据采集和关键信息提取技术构成的。
2.1 数据采集
网络爬虫是当前主流网络搜索引擎使用的技术,也是舆情监测工具中处理网页获取、网页跟踪、网页分析、网页搜索、网页评级和结构/非结构化数据抽取以及后期更细粒度的数据挖掘等方方面面的主要工具。
网络爬虫的实现方式是通过访问网页中的超文本链接,自动抓取互联网内部的程序或者脚本。
2.2 通用型爬虫与主题性爬虫介绍
当前主流的网络爬虫技术主要分为通用型网络爬虫技术和主题性网络爬虫技术。通用型网络爬虫的主要目标是大量采集信息页面[1],有较高的网络覆盖率,但其盲目的抓取会下载大量的垃圾页面,浪费网络资源。
主题型爬虫以自定义的主题信息为出发点抓取信息,基于此假设:如果网页U与主题相关,并且页面V到网页U通过一个超链接进行连接,那么抓取页面V的主题相关度比从网页中随机抓取的页面相关度要高。[2] 与通用型爬虫不同之处在于主题型爬虫可专门面向某一特定主题进行搜索,对于质检行业所关注的产品、标准、项目有更好的适应性。
2.3 主题型爬虫的工作方式
主题型爬虫的运行过程大致为:
1. 将搜索到的页面和各种信息项放到一个信息集合项中;
2. 分析每个信息项,将其中的基本信息单元作为索引,并形成索引库。同时建立一个存储Web页面的metadata数据库。
3. Web浏览器将用户通过浏览器的查询请求通过HTTP协议传到搜索引擎,搜索引擎利用索引库找到相关文档并返回Web页面,或者将URL列表以及相应的摘要反馈给Web浏览器的用户查询界面。
4. 用户获得Web页面摘要信息或者信息项的列表,若想查看其中具体的内容,则点击标题访问,浏览器在matadata数据库的支持下通过HTTP协议从信息的原始位置取回Web页面或其他信息。
2.4 主题型爬虫的爬行策略
实现主题型爬虫最常用的策略是PageRank和HITS算法,其共同点是根据页面与主题的相似程度来确定主题的相关度,并根据主题的相关度来评估子网页的重要性。[3]
RageRank算法可以得出网页的重要程度,进而对其权威性进行评价。
HITS算法也是一种通过网页链接来评估网页重要性的算法。相较于PageRank算法,HITS算法在网页链接与用户需求主体的关联性上有所改进。
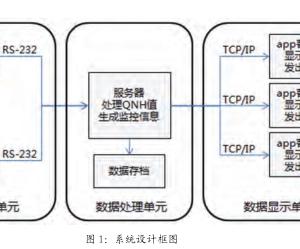
3 质量舆情系统架构设计研究
质量舆情系统统是一个分布式互联网数据搜集与挖掘系统,系统的模块分为6层:数据抓取、数据预处理、数据提取、数据索引、数据检索、API/Web service与平台展示。
3.1 数据预处理
预处理包括网页噪音去除和语义分析。
噪音去除:
对抓取到的数据进行噪音去除,包括网页周边广告和版权声明。对保留的有效内容,逐句做正负面判定,以及品牌、属性词条的露出标注。并将预处理后的信息入库保存。
语义分析:
1,
智能语义分析:基于基础的分词词典、正负面词典、15个领域的知识库和句法分析算法,可以自动的对网络信息进行实体、属性识别以及正负面判定,从而实现了海量信息下的口碑分类与危机识别。
2,
半结构化信息的自动提取:可以自动提取互联网网页中的有用信息,保存到结构化的数据库中实现方便的查询,如网络论坛中的分楼、帖子作者、时间、点击数、回复数等。
3,
海量文本的分类与聚类:可灵活的为各种分类体系训练相应的分类器,适应应用场景中多变的分类需求。基于LDA改进算法的聚类结果,可以充分挖掘语义层的关联,进行大规模的文本聚类,并进一步应用到互联网内容传播中的话题管理与新话题发现。
4,
内容关联性分析:基于FSP、卡方、Word2Vec等各种算法开发的内容关联性分析,适合各种不同应用场景中的关联发现需求,产品-属性、产品-竞品、产品-广告匹配,等等。
5,分词与领域内命名实体识别:常规自动发现互联网新词、领域内新词、以及领域内的命名实体识别,从而在应用中更为准确的定位目标实体。
3.2数据提取
提取出网页中内容的结构化数据并入库保存,供报告统计和前台查询时使用。结构化数据包括文章的作者、时间、发布站点、点击、回复、阅读、评论、点赞等。动态指标数据可以根据需求做定期更新。对于页面中的互动内容,如论坛的分楼回复、新闻下评论、可以做精细化提取为作者、时间、回复内容。互动内容需要根据站点做定制开发,目前覆盖热门100个论坛,以及4大门户的新闻评论。
3.3数据索引
为了提供快速的关键词检索,系统采用倒排表作为文本内容的索引。为提高效率,系统索引分为三级。当日内的数据放在一级索引里,本周数据放在二级索引里,本周前的数据放在三级索引里。每日抓取回的数据每小时都会更新到一级索引里。当抓取内容进入索引后,就可以提供对外的查询。
3.4数据检索
用户在平台上做监测关键词配置后,系统的数据检索模块会定期对后台的索引进行检索,筛选出来符合平台配置的文章,放到平台上提供展示和统计筛选。对于有特殊需求的客户,比如危机预警客户,可以定制平台数据更新频次和时间点,从而实现平台更频繁更新。
数据检索的过程既包括文本内容的检索,也包括对于内容的元数据的关联,比如,检索出论坛文章后,同时关联出文章的作者、时间、点击、回复等信息。
3.5 平台信息展示与API数据接口
系统通过Web 服务的方式,呈现监测对象的相关数据,并按照时间、站点、正负面、作者等维度进行数据筛选。并在数据基础上统计出热门话题、负面话题、热词云图等数据统计结果。
4 结束语
我国的质检行业面临的市场化的挑战,而当前质检行业对信息技术手段的利用离现代企业管理还有差距。舆情监测系统能够帮助质量监管部门获取当前市场上最关注的的质量问题。我国的质检行业面临的市场化的挑战,而当前质检行业对信息技术手段的利用离现代企业管理还有差距。舆情监测系统能够帮助质量监管部门获取当前市场上最关注的的质量问题。通过网络舆情监测系统,利用计算机网络技术的优势,系统、科学、高效的分析和预警质量信息,是质量监管部门维护社会稳定,保护企业形象的基础保障。但是对于怎样挖掘更深入的信息,怎样对挖掘的信息进行风险等级评价,依然需要深入研究。
参考文献
[1]
王桂梅.主题网络爬虫关键技术研究[D].哈尔滨工业大学,2009.
[2]
丁杰,徐俊刚.IPSMS:一个网络舆情监控系统的设计与实现[J].计 算机应用与软件,2010(4)
[3]
刘毅, 网络舆情研究概论[M],天津;天津出版社,2007